Depuis des années, les chercheurs en intelligence artificielle cherchent à repousser une limite invisible : la taille de la mémoire des modèles de langage. Cette mémoire, appelée « fenêtre de contexte », détermine la quantité d’informations qu’un modèle peut prendre en compte pour raisonner. DeepSeek, vient de proposer une solution radicale : convertir le texte en image pour le comprimer massivement, sans perte majeure d’information. Son modèle DeepSeek-OCR redéfinit ainsi le rapport entre texte, image et mémoire des IA.
Sommaire
Une idée simple : une image vaut mille mots
L’intuition de départ est presque poétique : une image contient plus d’informations qu’une suite de mots. Dans DeepSeek-OCR, cette métaphore devient une réalité technique. L’équipe a découvert qu’un texte rendu sous forme d’image pouvait être traité par un modèle de vision beaucoup plus efficacement qu’en format texte pur.
Résultat : une compression d’environ 10× tout en conservant 97 % de précision à la relecture. À 20×, la précision tombe encore à 60 %, mais le gain en densité reste vertigineux.
Autrement dit, une page de texte représentant 3 000 tokens peut devenir une image n’en nécessitant que 300. Dans le monde des grands modèles de langage, où chaque token coûte en mémoire et en calcul, c’est une révolution.
Le goulet d’étranglement des LLM : la fenêtre de contexte
Pour comprendre l’impact, il faut revenir à la mécanique interne des LLM comme GPT, Claude ou Gemini. Ces modèles « lisent » leur environnement (le prompt) à travers une fenêtre de contexte : plus elle est large, plus le modèle peut intégrer d’informations cohérentes, mais le coût de calcul augmente de façon quadratique.
Ainsi, doubler la taille de la fenêtre multiplie les besoins en GPU et en mémoire, freinant les avancées vers des IA capables de « raisonner » sur de très longs documents, comme un dossier juridique complet ou l’historique d’une conversation.
DeepSeek-OCR propose une alternative : compresser le contexte non pas par le texte, mais par la vision. Une sorte de « zip optique » pour l’intelligence artificielle.
Comment fonctionne DeepSeek-OCR
Le pipeline de DeepSeek-OCR repose sur deux briques principales :
1. Le DeepEncoder, un encodeur de 380 millions de paramètres qui transforme le texte rendu en image en une suite de vision tokens. Il combine un module de vision locale (de type SAM) et une compression convolutionnelle (jusqu’à 16×), enrichie d’un modèle global (proche de CLIP).
2. Le DeepSeek 3B-MoE, un décodeur de 3 milliards de paramètres utilisant une architecture mixture of experts (570 M actifs par requête) pour reconstituer le texte original, y compris dans des documents complexes contenant tableaux, formules, ou caractères multilingues.

Le modèle a été entraîné sur 30 millions de pages PDF couvrant une centaine de langues, principalement anglais et chinois.
Résultat : sur un jeu de données standard, 100 vision tokens suffisent pour reconstituer 700 à 800 mots, soit environ 10× de compression effective.
Pourquoi ça change tout: vers une mémoire visuelle des IA
L’impact de cette innovation dépasse le cadre de l’OCR. En transformant le texte en image, DeepSeek propose une nouvelle conception de la mémoire des IA.
Plutôt que d’étendre indéfiniment les fenêtres de contexte — une stratégie coûteuse et techniquement limitée —, il devient possible d’archiver de grandes quantités de texte sous forme compressée. Une IA pourrait ainsi « relire » d’anciennes informations visuelles en réinjectant ces images compressées dans son raisonnement.
C’est une approche qui rapproche les LLM de la cognition humaine : notre mémoire visuelle est capable de stocker de larges ensembles d’informations sous forme d’images mentales, et d’en extraire rapidement des éléments pertinents sans se souvenir de chaque mot.
Les implications à long terme
Plusieurs chercheurs, dont Andrej Karpathy (ex-OpenAI, Tesla), ont commenté cette avancée. Selon lui, il serait logique à terme que tous les modèles de langage utilisent des images comme format d’entrée, même pour le texte pur :
« Peut-être que les pixels sont de meilleurs inputs que les tokens », écrit-il. « Supprimez le tokenizer : c’est une couche inefficace. »
Si cette intuition se confirme, les LLM pourraient bientôt fonctionner sur des représentations multimodales unifiées — un même flux d’images pour traiter texte, mise en page, tableaux et schémas.
Cela ouvrirait la voie à des fenêtres de contexte 10× à 20× plus grandes, mais aussi à des mémoires persistantes, capables de stocker de vieux prompts recompressés sous forme d’images. Il est possible d’imaginer de stocker toute la connaissance d’une entreprise sous forme d’image et ensuite l’interroger avec un chatbot standard.
Dans ce futur, une IA pourrait relire en une seule passe l’équivalent d’une encyclopédie ou de plusieurs années d’échanges, sans explosion des coûts de calcul.
Une révolution discrète mais structurante
DeepSeek-OCR n’est pas qu’un outil d’OCR performant : c’est une expérimentation de ce que pourrait devenir la mémoire des IA.
En combinant vision et langage, le modèle introduit un paradigme de compression contextuelle qui pourrait réécrire les règles de l’entraînement, de l’inférence et de la conception des futurs agents intelligents.
Si l’histoire de l’IA est jalonnée de bonds techniques (Transformer, attention, mixture of experts), celui-ci agit plus en profondeur : il transforme la manière dont les IA voient et se souviennent.
DeepSeek-OCR est moins une innovation de reconnaissance de caractères qu’un prototype de mémoire visuelle universelle. En réduisant drastiquement le coût d’accès au contexte, il trace la route vers des modèles réellement capables de penser dans la durée — une étape décisive vers l’intelligence artificielle à mémoire longue. La frugalité en marche.
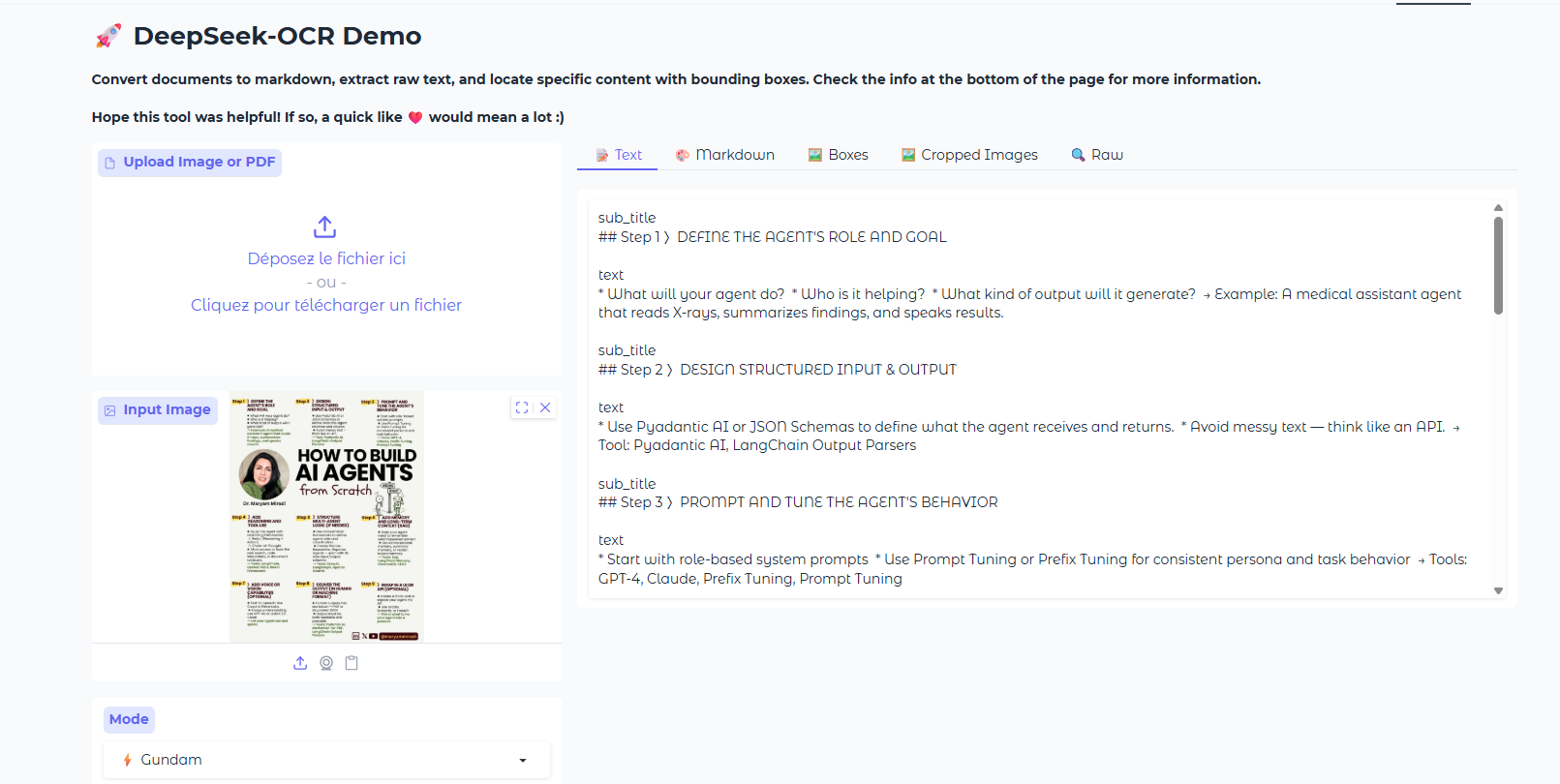
Pour tester Deepseek OCR sur HugginFace : https://huggingface.co/spaces/merterbak/DeepSeek-OCR-Demo


Laisser un commentaire