Le “blitz” médiatique de Google cette semaine donne le tournis : déploiement mondial de Gemini 3.1 Flash Live, intégration de fonctions de migration agressive pour aspirer l’historique des chatbots concurrents, et ouverture stratégique d’Apple via ios 27. Si le duel entre le “modèle-roi” (google) et le “matériel-hôte” (apple) occupe le terrain marketing, la véritable secousse tellurique est ailleurs. Dans l’ombre des annonces grand public, Google Research a publié un article sur une nouvelle approche de l’IA : Turboquant. Derrière ce nom technique se cache une technologie de compression capable de réduire l’empreinte mémoire de l’ia par 6, sans aucune dégradation de précision. Une sorte de MP3 de l’IA.
Pour être synthétique, cette annonce est le signal d’un changement de paradigme économique : l’ia s’apprête à devenir radicalement moins chère, plus agile et, surtout, véritablement autonome. Pour bien comprendre l’enjeu, rappelons que le modèle économique des industriels de l’IA repose sur le coût total par token. En compressant par un facteur 6 ou 8 le traitement de l’inférence et sa vitesse à qualité égale, le coût au token est potentiellement divisé d’autant. Théoriquement, cela induit une réduction des coûts d’abonnement (ou pas), mais surtout des fenêtres de contexte plus étendue et de nouvelles fonctionnalités.
Sommaire
Pourquoi ? Le goulot d’étranglement : La “mémoire vive” des llms
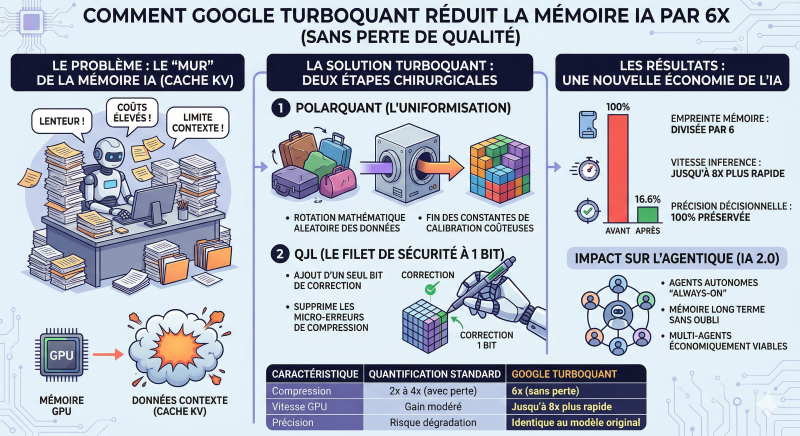
Pour comprendre l’impact de Turboquant, il faut identifier le frein principal des modèles actuels : le « cache kv » (key-value).
Imaginez un traducteur simultané qui doit traduire une conférence de 4 heures. Pour ne pas perdre le fil et rester cohérent, il doit garder en tête chaque phrase prononcée depuis le début de la matinée. Plus la conférence avance, plus son cerveau sature d’informations à maintenir “en ligne”. Nous avons tous été bloqués à un moment ou à un autre par une fenêtre de contexte qui se referme progressivement avec des réponses de plus en plus bâclées. Plus vous demandez au modèle d’analyser un document long ou de maintenir une conversation complexe, plus il remplit la mémoire de son processeur (gpu) avec ces données de contexte. C’est ce qui rend l’ia coûteuse : on manque de place sur les puces pour servir beaucoup d’utilisateurs en même temps. C’est le mur de l’inférence.
La méthode turboquant : Une chirurgie en deux temps

Jusqu’ici, pour gagner de la place, on utilisait la « quantification » classique. C’est l’équivalent de prendre un texte écrit avec une calligraphie parfaite et de le réécrire de façon très brouillonne pour qu’il tienne sur un timbre-poste. On gagne de la place, mais on finit par ne plus pouvoir relire certaines lettres (perte de précision).
Turboquant change la donne avec une approche chirurgicale inédite :
- Polarquant : Le passage par la boussole
Au lieu de stocker les informations comme des coordonnées sur une carte quadrillée (x, y), Polarquant les traite comme un vecteur sur une boussole (un angle et une distance). Imaginez que vous deviez ranger des valises de tailles et de formes totalement disparates dans un coffre. C’est un casse-tête car chaque vide entre les valises est une perte de place. Turboquant fait d’abord “pivoter” virtuellement toutes ces valises pour qu’elles aient exactement le même profil aérodynamique. Une fois uniformisées, elles s’empilent parfaitement sans laisser de vide. On gagne une place immense sans avoir à forcer sur les serrures.
2. Qjl : Le filet de sécurité à 1 bit
Même avec un rangement parfait, il reste toujours un infime décalage mathématique. Pour le corriger, Turboquant ajoute une micro-couche de vérification : le qjl (quantized johnson-lindenstrauss).
C’est comme un signal “vrai/faux” ultra-léger qui vient valider chaque donnée compressée. C’est une correction d’erreur si subtile qu’elle ne pèse quasiment rien, mais elle garantit que le message reconstruit est strictement identique à l’original.
Le catalyseur de l’ère agentique (IA 2.0)
Si Turboquant est une victoire pour l’efficacité des chatbots, c’est une révolution totale pour l’agentique. Un agent n’est pas juste un chatbot ; c’est une entité qui pense, planifie et agit en boucle. Jusqu’à présent, trois verrous bloquaient leur déploiement massif. Turboquant les fait sauter. Un agent efficace doit jongler avec des flux de données massifs : documentation technique, logs serveurs, état des api et objectifs long terme. Plus l’agent “réfléchit” longtemps, plus son cache kv explose. En divisant l’empreinte mémoire par 6, Turboquant permet à un agent de maintenir un contexte haute fidélité sur des sessions de plusieurs jours. L’agent ne “décroche” plus au milieu d’une tâche complexe.
La fin de la latence de réflexion (loop speed)
L’agentique repose sur des boucles de rétroaction : l’agent observe, pense, agit, puis analyse le résultat. Si chaque cycle de pensée prend 10 secondes à cause de la lourdeur du modèle, l’agent est inutilisable en production réelle. Avec une accélération jusqu’à 8x sur les calculs d’attention, la “boucle de raisonnement” devient quasi instantanée. Un agent peut désormais s’auto-corriger 8 fois plus vite, rendant l’automatisation fluide et naturelle.
La viabilité du “multi-agent”
Le graal de l’automatisation est de faire travailler une escouade d’agents spécialisés (veille, synthèse, exécution). Actuellement, faire tourner 5 agents coûte 5 fois le prix d’une requête. Turboquant permet de densifier l’infrastructure. On peut faire tourner une équipe entière d’agents sur le même gpu qui n’en supportait qu’un seul auparavant. La rentabilité du multi-agent devient enfin une réalité pour les pme.
Pourquoi c’est un “game changer” business
Les chiffres publiés par Google Research sont sans appel : sur des modèles comme Gemma ou Mistral, le cache kv est divisé par 6, la vitesse est multipliée par 8, et la précision reste de 100%. Si Turboquant est rapidement adopté, et les premières implémentations open source sur puces Apple et vllm prouvent que c’est déjà le cas, nous quittons l’ère de la “force brute” logicielle pour entrer dans celle de l’efficience algorithmique pure.
La libération de l’ia : du cloud au terminal local (edge ia)
L’autre onde de choc de Turboquant concerne la fin de la dépendance absolue aux data centers. Jusqu’ici, faire tourner un modèle de langage performant sur un smartphone ou un laptop se heurtait à la limite physique de la vram. En divisant par 6 l’empreinte du cache kv, Google brise les chaînes de l’ia “cloud-only”. Cela signifie que des modèles puissants peuvent désormais s’installer confortablement dans la ram d’un iphone ou d’un pc de bureau standard. L’intelligence devient locale, privée et, surtout, disponible hors-ligne, transformant chaque appareil en une unité de raisonnement autonome et souveraine.
Cette transition vers l’ia “on-device” redéfinit radicalement la stratégie it des entreprises. En déportant le calcul du cloud vers le terminal de l’utilisateur, on élimine la latence réseau et on sécurise les données sensibles qui ne quittent plus jamais le périmètre physique de l’appareil. Pour un consultant, c’est une opportunité majeure : on peut envisager le déploiement d’agents complexes sur des flottes de matériel existantes, sans obliger le client à investir dans des serveurs prohibitifs. Turboquant ne se contente pas d’optimiser le code ; il démocratise l’accès à une ia de haute volée pour chaque collaborateur.
L’ia ne devient pas seulement plus intelligente, elle devient enfin économiquement viable à grande échelle. Ce qui était trop lourd ou trop cher hier sera la norme de demain. En termes de timing, il faudra sans doute entre 12 et 18 mois pour qu’il soit déployé à l’échelle.
A lire : TurboQuant: Redefining AI efficiency with extreme compression


Laisser un commentaire